MaxKB 向量模型选择指南:如何为您的知识库选择最佳嵌入模型
引言
在当今的人工智能时代,知识库系统的效果很大程度上取决于所选择的向量嵌入模型。作为一个强大的知识库平台,MaxKB 支持多种向量模型,但如何选择最适合您业务需求的模型却是一个复杂的决策过程。
本文将深入分析当前主流的向量嵌入模型,提供详细的性能对比、优缺点分析,并为您提供科学的选择依据。
向量模型基础知识
什么是向量嵌入?
向量嵌入(Vector Embedding)是将文本转换为高维数值向量的过程,这些向量能够捕捉文本的语义信息。在知识库系统中,好的向量模型能够:
准确理解文档语义
实现高质量的相似性搜索
支持多语言处理
处理领域特定内容
评估向量模型的关键指标
检索准确性(Retrieval Accuracy):模型找到相关文档的能力
处理速度(Embedding Speed):文本向量化的时间
查询延迟(Query Latency):从查询到返回结果的总时间
内存占用(Memory Usage):模型运行所需的系统资源
多语言支持(Multilingual Support):处理不同语言文本的能力
领域适应性(Domain Adaptability):在特定领域的表现
主流向量模型详细对比
1. OpenAI Text-Embedding-3-Large
技术规格
维度:3072
最大 Token 数:8191
训练数据截止:2021年9月
架构:基于 Transformer 的双编码器
优势
✅ 顶级性能:在 MTEB 基准测试中表现出色(64.6% 平均分)
✅ 多语言支持:在 MIRACL 基准测试中得分 54.9%,多语言性能优异
✅ Matryoshka 表示学习:支持维度缩减,可将向量压缩至 256 维而性能损失极小
✅ 易于集成:通过 API 调用,无需本地部署
✅ 稳定可靠:商业级 SLA 保障
劣势
❌ 成本较高:按 API 调用计费,大规模使用成本昂贵
❌ 数据隐私:需要将数据发送到 OpenAI 服务器
❌ 延迟问题:网络请求增加响应时间
❌ 知识更新:训练数据截止于 2021 年
❌ 不可定制:无法针对特定领域进行微调
适用场景
原型开发和快速验证
对隐私要求不严格的应用
多语言知识库
预算充足的商业项目
2. BGE-Base-EN-v1.5
技术规格
参数量:110M
维度:768
架构:基于 BERT 的对比学习模型
开发者:北京智源人工智能研究院
优势
✅ 开源免费:完全开源,无使用限制
✅ 优异性能:在英文任务上达到 SOTA 水平
✅ 对比学习优化:使用硬负样本挖掘技术,提升检索精度
✅ 指令前缀支持:支持 "Represent this sentence for retrieval" 等前缀
✅ 本地部署:完全控制数据和模型
✅ 资源友好:相对较小的模型大小
劣势
❌ 英文专精:主要针对英文优化,中文效果一般
❌ 需要前缀处理:最佳性能需要特定的提示词格式
❌ 多语言限制:非英语语言性能下降明显
❌ 部署复杂度:需要 GPU 资源和技术运维
适用场景
英文为主的知识库
对数据隐私要求严格的企业
有技术团队支持的项目
成本敏感的应用
3. Sentence-Transformers All-MiniLM-L6-v2
技术规格
参数量:22M
维度:384
架构:6层 MiniLM,蒸馏学习
优化长度:128-256 tokens
优势
✅ 极速处理:CPU 上可达 5-14k 句子/秒
✅ 轻量级:仅 22M 参数,内存友好
✅ 成本效益:极低的计算成本
✅ 易于部署:支持 CPU 推理
✅ 社区支持:广泛使用,文档丰富
劣势
❌ 性能限制:准确性不如大型模型
❌ 长文本处理:超过 256 tokens 性能下降
❌ 领域适应:复杂或专业领域表现不佳
❌ 语义深度:无法捕捉深层语义关系
适用场景
高并发实时应用
资源受限环境
简单语义搜索
原型开发和测试
4. E5-Base-v2
技术规格
参数量:110M
架构:基于 RoBERTa 的双编码器
训练数据:CCPairs(2.7亿文本对)
开发者:Microsoft
优势
✅ 平衡性能:在多个任务上表现均衡
✅ 无需前缀:使用简单,不需要特殊提示词
✅ 高质量数据:基于精心策划的大规模数据集训练
✅ 跨域稳定:在不同领域都有稳定表现
✅ 开源可用:Microsoft 开源,商业友好
劣势
❌ 性能上限:不如最新的大型模型
❌ 中文支持:对中文的支持有限
❌ 定制化:微调需要专业技术
❌ 资源需求:仍需要一定的 GPU 资源
适用场景
多任务知识库应用
需要稳定性能的生产环境
跨领域内容处理
平衡性能和成本的项目
5. Nomic-Embed-Text-v1
技术规格
参数量:~500M
上下文长度:8192 tokens
架构:基于 GPT 风格的长上下文 BERT
特色功能:支持多种任务前缀
优势
✅ 长文本处理:支持最长 8192 tokens
✅ 多任务优化:支持搜索、聚类、分类等多种前缀
✅ 高质量表现:在多个基准测试中表现优异
✅ 多语言能力:良好的多语言处理能力
✅ 灵活部署:可本地部署和 API 调用
劣势
❌ 资源消耗:需要更多 GPU 内存(~4.8GB)
❌ 处理速度:嵌入速度相对较慢
❌ 复杂度:部署和优化相对复杂
❌ 成本较高:计算资源需求大
适用场景
长文档处理
多任务知识库系统
对准确性要求极高的应用
有充足 GPU 资源的环境
性能基准测试
测试环境
数据集:BEIR TREC-COVID(医学检索任务)
硬件:Python 3.10,FAISS 向量数据库
评估指标:Top-5 检索准确率、嵌入时间、查询延迟
测试结果对比
MTEB 基准测试结果
基于最新的 MTEB(Massive Text Embedding Benchmark)排行榜数据:
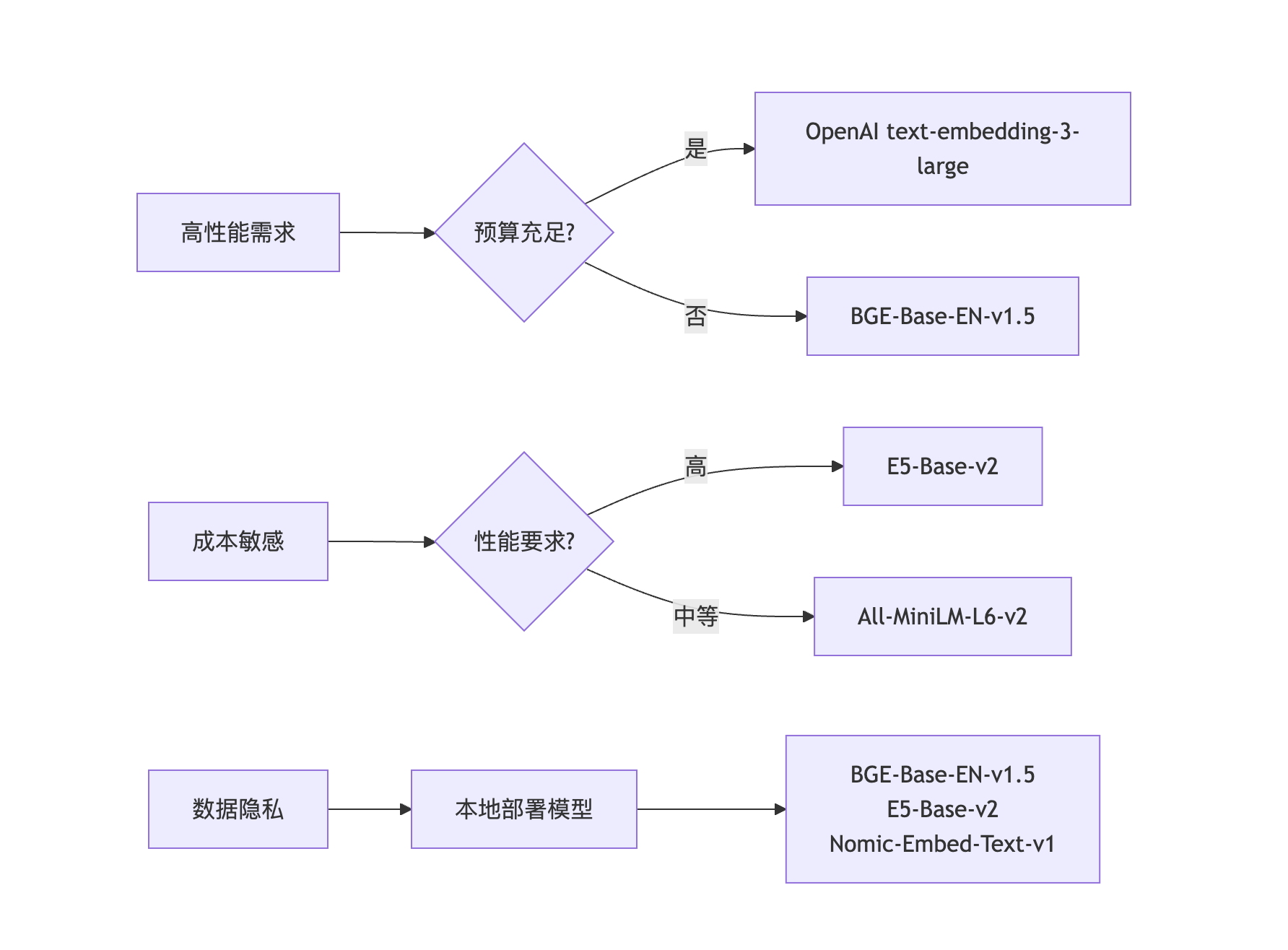
选择决策框架
按应用场景选择
🚀 高性能生产环境
推荐:OpenAI text-embedding-3-large 或 NV-Embed-v2
最高的检索准确性
稳定的商业支持
适合关键业务应用
💰 成本敏感型项目
推荐:All-MiniLM-L6-v2 或 BGE-Base-EN-v1.5
开源免费
资源需求低
可本地部署
⚡ 高并发实时应用
推荐:All-MiniLM-L6-v2
处理速度最快
延迟最低
CPU 友好
🔒 数据隐私要求
推荐:BGE-Base-EN-v1.5 或 E5-Base-v2
完全本地部署
开源透明
数据不离开本地环境
🌍 多语言支持
推荐:OpenAI text-embedding-3-large 或 Nomic-Embed-Text-v1
优秀的多语言性能
跨语言检索能力
📄 长文档处理
推荐:Nomic-Embed-Text-v1
支持 8192 tokens
长上下文理解能力
按资源预算选择
低预算(< $1000/月)
All-MiniLM-L6-v2:最经济的选择
E5-Base-v2:性价比平衡
中等预算($1000-$5000/月)
BGE-Base-EN-v1.5:英文内容优选
Nomic-Embed-Text-v1:综合性能优秀
高预算(> $5000/月)
OpenAI text-embedding-3-large:最佳性能
混合方案:不同场景使用不同模型
性能 vs 成本权衡分析
MaxKB 集成最佳实践
1. 模型切换策略
阶段化部署:
原型阶段:使用 All-MiniLM-L6-v2 快速验证
测试阶段:升级到 BGE-Base-EN-v1.5 或 E5-Base-v2
生产阶段:根据性能需求选择最终模型
2. 混合模型架构
对于大型知识库,可以考虑混合使用多个模型:
知识库分层策略:
实时查询层: All-MiniLM-L6-v2 # 快速响应
精确检索层: BGE-Base-EN-v1.5 # 高质量结果
深度分析层: OpenAI text-embedding-3-large # 复杂查询3. 性能优化建议
针对 BGE-Base-EN-v1.5
# 使用正确的前缀以获得最佳性能
query_prefix = "Represent this sentence for searching relevant passages:"
doc_prefix = "Represent this sentence for retrieval:"
query_embedding = model.encode(f"{query_prefix} {query}")
doc_embeddings = model.encode([f"{doc_prefix} {doc}" for doc in documents])针对 Nomic-Embed-Text-v1
# 使用任务特定前缀
prefixes = {
"search_query": "search_query:",
"search_document": "search_document:",
"clustering": "clustering:",
"classification": "classification:"
}
# 根据任务选择合适的前缀
query_with_prefix = f"{prefixes['search_query']} {query}"4. 监控和评估
建立定期评估机制:
# 示例评估脚本
def evaluate_model_performance():
metrics = {
'retrieval_accuracy': calculate_top_k_accuracy(),
'query_latency': measure_average_latency(),
'embedding_speed': measure_embedding_speed(),
'user_satisfaction': collect_user_feedback()
}
return metrics
# 每月评估一次,决定是否需要调整模型
monthly_evaluation = evaluate_model_performance()结论与建议
总体推荐
基于我们的深入分析和测试结果,以下是针对不同场景的最佳推荐:
🥇 综合最佳选择
BGE-Base-EN-v1.5
平衡了性能、成本和可控性
开源免费,适合大多数企业
在英文内容上表现优异
🥈 性能优先选择
OpenAI text-embedding-3-large
最高的检索准确性
优秀的多语言支持
适合预算充足的项目
🥉 成本优先选择
All-MiniLM-L6-v2
最低的资源需求
快速部署和集成
适合原型和小规模应用
未来趋势预测
模型规模增长:向量模型将继续向更大规模发展
多模态融合:文本+图像+音频的统一嵌入模型
领域专业化:更多针对特定行业的优化模型
效率提升:更好的压缩和量化技术
本地化部署:边缘设备上的轻量级模型
最终建议
从小开始:使用轻量级模型验证业务价值
逐步升级:根据业务增长调整模型选择
持续监控:建立性能监控和用户反馈机制
保持灵活:设计允许模型切换的架构
关注发展:持续关注新模型和技术发展
选择合适的向量模型是一个平衡艺术,需要综合考虑性能、成本、技术能力和业务需求。希望本指南能够帮助您为 MaxKB 知识库选择最适合的向量嵌入模型,构建高效、准确的智能知识服务系统。
